DON’T Use Speech Recognition in Language Learning Apps
After researching ~100 language learning apps in South East Asia and the American app market, I found that only 27% allow users to practice speaking, and most of them use speech recognition as speaking feedback.
Using speech recognition is ineffective in language learning for two reasons.
1. Good pronunciations are all alike; every mispronunciation is faulty in its own way.
One of the barriers to language learning is the mother tongue, especially for learners 12 years old and above. Deeply influenced by the sound system of their mother tongues, language learners may confuse sounds in their mother tongue with those in a new language. There are over 7000 languages globally, so a single language corresponds to a broad spectrum of mispronunciations from language learners.
It is happy if a recognition system can recognize speech, but what matters the most is how to deal with mispronunciations, which fail the recognition system. It can not shed light on where and how to improve, but those are where learners should put more effort.
2. Speech recognition is inaccurate when recognizing words.
Words are building blocks of sentences. Trying to speak words first, then putting them together into sentences is classic speaking practice. However, speech recognition is inaccurate in recognizing words.
Traditionally, speech recognition relies on a language model and an acoustic model. However, when recognizing a single word, only acoustic model is involved because the language model can only provide unigram probability but no more.
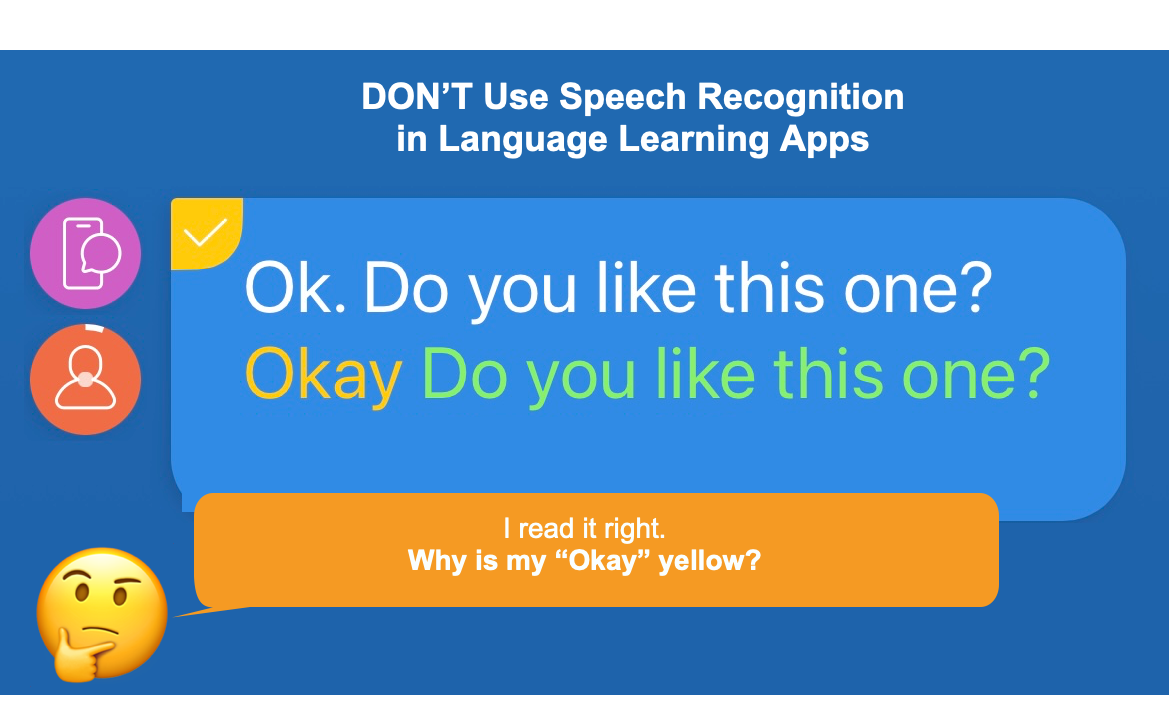
So it’s highly possible that when you read the word “OK” correctly, the app tells you that you’re wrong because the recognition result is “Okay”. Speech recognition can not tell apart homonyms.
In summary, if language learning apps make *an efficient learning experience* a priority, then they need to rethink what they need. Not a speech recognition system for speaking practice, at least.
At SpeechSuper, we develop AI-based speech technologies to analyze speech from language learners, including pronunciation, fluency, completeness, and more. If you’re interested, please contact us on the website.
ABOUT US
Qiusi is a product manager in China’s EdTech industry focusing on language learning and AI. She enjoys writing stories. You can reach her at qiusi.dong@speechsuper.com
SpeechSuper provides cutting-edge AI speech assessment (a.k.a pronunciation assessment or pronunciation score) APIs for language learning products. Comprehensive feedback covers pronunciation score, fluency, completeness, rhythm, stress, liaison, etc. Languages supported include English, Mandarin Chinese, French, German, Korean, Japanese, Russian, Spanish, and more.
*Prior written consent is needed for any form of republication, modification, repost, or distribution of the contents.



Comments
Post a Comment